 |
| Optimal output from the
Abbe Budget microscopy .........A case for bending the rules? By Paul James, UK |
This month's article concerns the Abbe condenser : the economical substage optic which I'm sure is employed on the the majority of amateur's microscopes worldwide. I hope that the following notes will help in elevating its lowly status within the illumination folklore of microscopy, reinforcing its usefullness to those who might believe the achromat/aplanat versions hold the key to a superior form of imaging. Though possession of the latter has obvious appeal, the differences between their image support capabilities hardly compares with their differences of intrinsic cost. In short, the Abbe can do the business well enough, but it needs a little understanding and coaxing to get the very best out of it. |
The Nature of the Problem
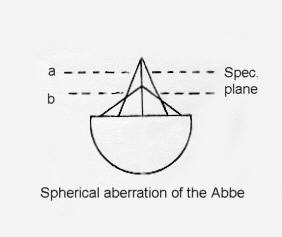
The Abbe condenser's principle weaknesses are of course its spherical and chromatic aberrations: the former being its worst flaw, from the substage manipulation point of view. Generally speaking most Abbe condensers have 2 elements, those with 3 tend to be aplanats: condensers with little or no spherical aberration. Though the degree of correction varies between examples from different manufacturers, the colour dispersion remains to a greater or lesser degree in all but the achromat/aplanat examples.
The Abbe's cone of light it forms on the specimen is distorted as we'd expect from severe spherical aberration, and manifests itself as a disproportionately tapering apex. The lower tiers 'b' produce the highest NA with lower NA ouput 'a' extending higher up:-
|
In use the Abbe is perfectly adequate for brightfield in low to medium power applications. Its flaws however begin to show when the demands of higher aperture are met with from the use of the x40 objective upwards, that is at around 0.6-0.70 NA and up, depending on the maximum aperture of the Abbe in question. A large number have been made to date, but a fair proportion of them have no legends to indicate their aperture status. A rough guess would have it that most are dry forms, with aperture limits of 1.0 NA or somewhat less in practice, the rest being oil immersion types of up to about 1.25 NA.
The Abbe is therefore incapable of delivering its whole gamut of NA in a fixed plane of elevation like the achromat/aplanat. Its weaknesses are compounded by the constraints of illumination setup procedures.
Little Bit of Rule Bending
Köhler/Critical illumination setup rules dictate illumination methodology, and in particular the one which advises us to focus the substage condenser on the leaf edges of the lamphouse condenser's iris diaphragm. The simple fact is that the Abbe is not capable of providing all objectives with the full light cones they require with this singular setting of the substage condenser. Whilst owners of the achromat/aplanat condensers can leave their condensers sharply focussed on their lamphouse diaphragms, and know that the geometry of the condenser's source imagery will fully illuminate all their objective's apertures, subject to modification with the condenser's iris, those who use the Abbe should take this dictum in the Köhler setting up procedure only as a guide: a starting point.
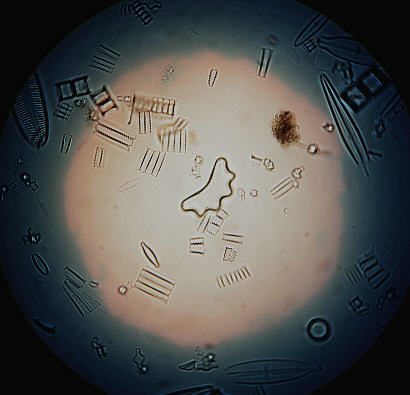
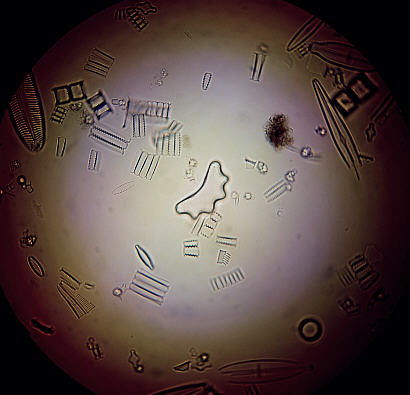
Instead we simply elevate the Abbe to make sure the higher NA cone optimises the filling of the objective's back lens. This is necessary when we employ a high NA objective. The first image below left shows the field restricted by the lamphouse iris as per Köhler setup. When the higher NA cone of the Abbe is brought onto the specimen by raising it a little we will bring about an image similar to that shown below on the right.
 |
 |
| Field iris edge focussed as per Köhler
setup. (Diatom. Achromat x 40 0.65 NA. 0.9 Dry Abbe ) Yielding dull low contrast image. |
Abbe now raised slightly to bathe specimen with higher NA cone. Note the change in field and also edge of iris appearance. Improvement in contrast and finer image quality |
So after elevating the Abbe to employ its higher NA cone onto the specimen, the lamphouse's iris diaphragm won't be sharp edged as traditional Köhler lighting advocates, but nevertheless its efficiency in filling the backlens of the higher NA objective is dramatically improved. Now the field boundary changes to a highly coloured fringe at the edges of the lamphouse iris, usually bright orange/red border, which will still prove effective enough to maintain contrast in the image. Fortunately this brightly coloured field boundary becomes the 'tell tale' that your Abbe is providing your objective with the higher NA cone it requires. The improvement of detail and contrast in the actual image will support this, as well as the view of the backfocal plane of the objective, where the filling of the objective's upper lens is only constrained by the Abbe's iris closure and not from the inappropriate elevation setting of the former as often the case with formal set up of in Köhler illumination.
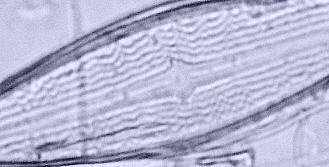
RESULTS OF RAISING ABBE WITH MAXIMUM FIELD IRIS CLOSURE.
Images below taken with same setup. Diatom (x 1200) x40 0.75 NA Fluo. Objct. Zeiss Abbe 0.9 NA flip top. Contrast increased using post image enhancement, and also scale amplified excessively: for illustrative purposes only
 |
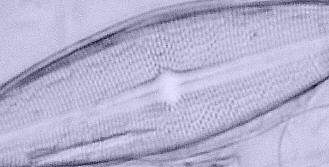 |
Image left above shows BF imagery with Abbe focussed on lamphouse iris. Above right shows image after raising the Abbe about 2.5mm. (Slight off centering of condenser imposed for illustrative effect.)
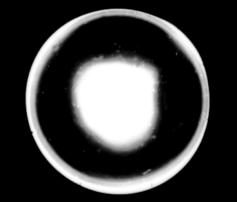 |
Back of objective lens view down eyepiece tube when the Abbe is raised even higher to manifest spherical aberration as 2 discrete concentric light zones. However, despite this severe flaw the Abbe can raise credible imagery :-
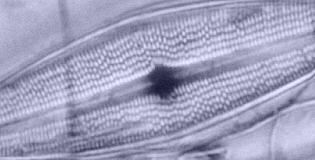 |
This image above is a curious mixture of BF, COL and DF generated from the concentrically zoned lighting, which may not be considered to be a viable or legitimate illumination technique, but rendered even more structural subtleties than the other settings of the Abbe. This particular effect is generated by closing the lamphouse iris to minimum, or nearly so, with a diffused source. Other examples of the Abbe gave slightly different results but were roughly comparable. As even this image indicates, the Abbe can coax a lot more out of a quality objective than generally given credit for.
Practice soon makes the optimisation of the Abbe a simple procedure which the eyes dictate naturally and automatically to the substage condenser's elevation control through the finger tips. Usually therefore there is less need to check the back focal plane of the objective, which ultimately means less dust entry inside!
When, after optimising the Abbe on a particularly detailed specimen, we revert the elevation of the condenser to bring about a sharp focus of the lamphouse diaphragm's iris at the edge of the field of view, the image will reveal a distinct degradation of the specimen's structure....the difference is very noticeable.
Concluding Thoughts
Hankering after a costly achromat/aplanat condenser is understandable as it certainly simplifies operational substage technique, and yields a more uniformly lit field of view required for the more sensitive uses such as photomicroscopy, but you might consider subduing your appetite for one if you feel this is too much on your pocket, more especially when the Abbe can be coaxed to squeeze a little more out of your quality high power objectives. I believe it pays to be rational regarding the apparent merits of exotic substage glassware. Upgrading however to a couple of fluorite/apochromatic objectives might prove as costly as an achromat/aplanat substage condenser, BUT of the two options, the one that gains you most obvious imaging clarity will not necessarily include the more highly corrected condenser. That the Abbe can easily reveal the superior optical performances of the fluorites/apo objectives alongside standard achromats, even with its inherent flaws, surely conveys an obvious message?
Careful manipulation of the Abbe's elevation along with critical use of both iris diaphragms, will certainly project a decent enough cone from the substage to satisfy the appetites of most objectives and the majority of observers for that matter, and might usefully prevent the personal disappointment I believe that could stem from the act of buying an expensive substage upgrade. Of course I wouldn't denigrate the achromat/aplanat condenser for a single moment, especially for high quality photomicroscopy, where faithful reproduction of colour is of paramount importance; but one wonders at the sensibility of situations that arise when examples of used microscope outfits (often of good quality) and these achromat/aplanat condensers are exchanged for similar money, which has I believe, more to do with human nature than physics.
However, if your Abbe presides over a well aligned diffused Köhler/Critical illumination source, and is tweaked accordingly, it will provide credible illumination that will serve for a lifetime's scrutiny with ease, suitably flattering your favourite subjects even through the lenses of classic hardware!
Comments to author welcomed.
Microscopy UK Front Page
Micscape
Magazine
Article
Library
Please report any Web problems or offer general comments to the Micscape Editor.
Micscape is the on-line monthly
magazine of the Microscopy UK web
site at
Microscopy-UK